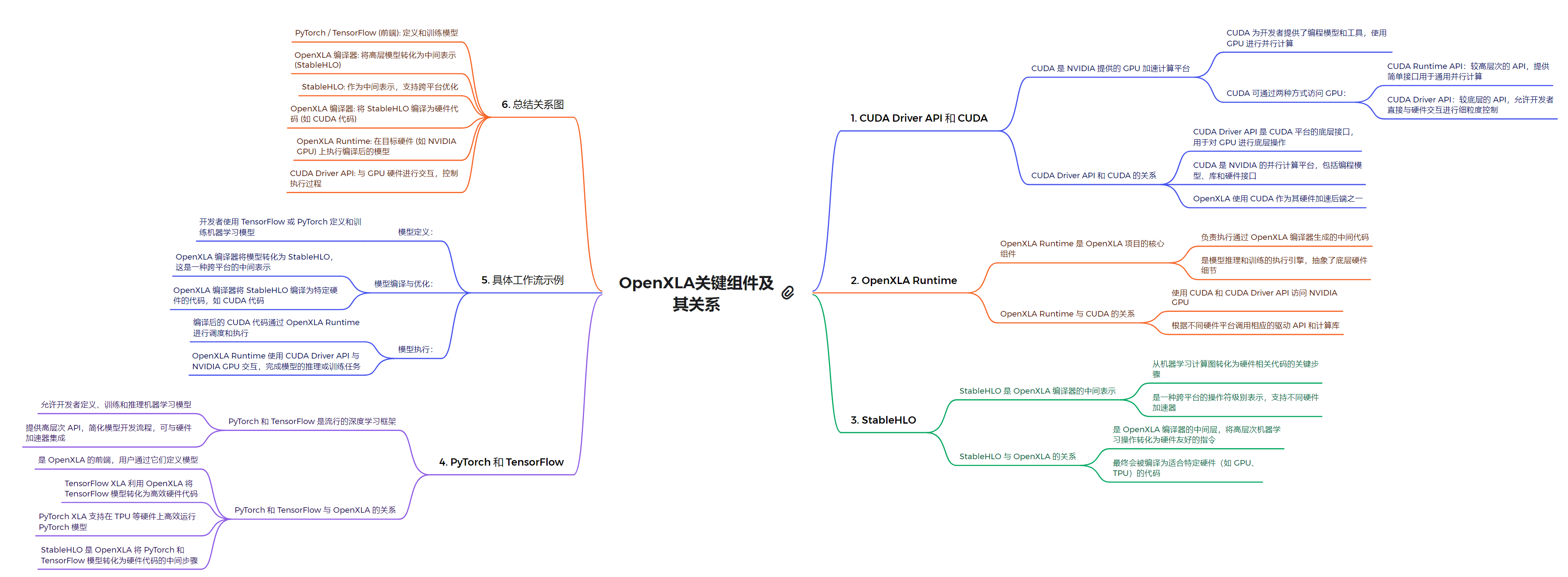
技术栈架构
1. 系统软件层
- CUDA Driver API:低级 API,提供对 NVIDIA GPU 的直接控制
- 允许直接管理设备、内存分配和程序执行
- 适用于需要细粒度控制的高级应用
- 为 OpenXLA 提供与 NVIDIA GPU 硬件交互的底层接口
2. 运行时环境层
- CUDA Runtime API:高级 API,简化了 GPU 编程,自动管理许多底层细节
- 为 OpenXLA 提供更高级的抽象,简化了 GPU 的使用
- 自动处理上下文管理和程序加载等任务
- OpenXLA Runtime:OpenXLA 框架的运行时环境
- 管理 OpenXLA 编译的模型的执行
- 支持多种硬件后端,包括 CUDA 设备
- 与 CUDA Runtime API 集成,提供对 NVIDIA GPU 的支持
3. 编程模型和语言层
- CUDA C/C++:扩展了 C/C++ 语言,允许开发者编写在 GPU 上运行的并行程序
- 为 OpenXLA 提供了一种与 NVIDIA GPU 交互的编程方式
- 可与 StableHLO 结合使用,实现对 CUDA 设备的优化
- StableHLO:OpenXLA 提供的高级中间表示语言
- 用于描述和优化机器学习模型
- 提供了一种声明式的方式来表达计算
- 可以针对 CUDA 设备等不同硬件后端进行优化
4. 计算库层
- NCCL:用于多 GPU 通信的库
- 支持多 GPU 之间的高效通信和数据交换
- 可与 OpenXLA 结合使用,支持分布式深度学习训练
5. 框架模型层
- PyTorch with OpenXLA:利用 OpenXLA 优化 PyTorch 模型在 CUDA 设备上的性能
- TensorFlow with OpenXLA:利用 OpenXLA 优化 TensorFlow 模型在 CUDA 设备上的性能
关系解析
OpenXLA 作为一个灵活的深度学习编译器框架,与 PyTorch 和 TensorFlow 深度集成,通过自定义算子、JIT 编译和 GPU 内核融合等技术,大幅提升了这些深度学习框架在 GPU 上的执行效率。同时,OpenXLA 还利用 CUDA Runtime API 和 CUDA Driver API,实现了对 GPU 硬件的精细控制和优化,包括内存管理、设备操作和内核启动等。这种多层次的架构设计使 OpenXLA 能够充分发挥 GPU 的计算能力,为开发者提供了一个高度灵活和易用的工具。此外,OpenXLA 还与 StableHLO 进行了深度集成,利用其提供的高级中间表示和优化技术,进一步增强了 OpenXLA 的性能和可扩展性。通过整合这些技术,OpenXLA 为开发者带来了显著的性能提升,同时简化了高性能深度学习应用的开发过程。